Discover your data-driven future
Research Highlights

Using a billionaire wealth tax to pay the tax liability of the poor
What would happen if a wealth tax on billionaires was used to pay the taxes of the poorest Americans? We created an interactive data visualization to find out how many Americans would have their taxes paid by a wealth tax.
Read more
Deconstructing Bloomberg's COVID Resilience Ranking
Despite their apparent objectivity, all scoring methodologies have embedded bias. We examine the bias in Bloomberg's COVID Resilience Ranking to determine whether it makes a difference to the Philippines, which found itself in last place.
Read moreInvited Talks

The Onion Architecture: A computational graph with appeal
We were invited to speak at the American Statistical Association on how computational graphs can facilitate reproducible science.
View Slides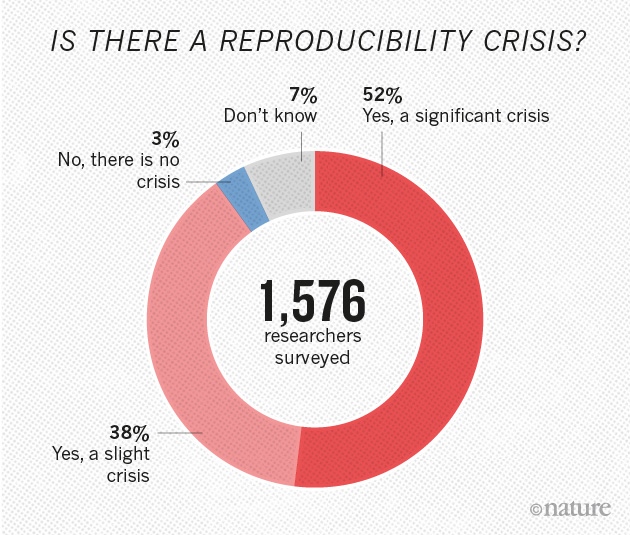
Achieving practical reproducibility with transparency and accessibility
We were invited to speak on reproducible science at the Data Science, Statistics, and Visualization conference hosted by the International Association for Statistical Computing.
View slides
Process automation as the backbone of reproducible science
We were invited to speak on reproducible science at the Symposium on Data Science and Statistics, hosted by the American Statistical Association.
View slides